EJB 3 Performance
Applications must be scalable and maintain high levels of availability, it is also expected to meet users expectations, performance concerns must be part of the design process, performance tuning can be applied to the application itself and the application server. In this topic i will only be focusing on the application side, for more information on application server tuning see JBoss tuning.
Concurrency issues can bring an application to its knees, dealing with concurrency is a nontrivial problem and must be address as early as the design phase. In a concurrent system you may run into one or more of the following issues involving multiple users, have a look at transactions for more in depth discussion.
| Dirty Read | Occurs when a user sees some uncommitted transactions from another user. |
| Nonrepeatable Read | Occurs when a user is allowed to change data employed by another user in a separate transaction |
| Phantom Read | Occurs when a user receives inconsistent results in two different attempts of the same query. |
There are two types of locking
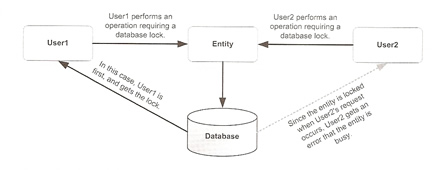
When using pessimistic locking, you lock all rows in the database that are involved for the entire time a user shows an interest in modifying an entity. JPA however does not support pessimistic locking but some providers do have vendor-specific extensions to use pessimistic locking. The diagram below shows a user may acquire two types of locks on an entity: write or read. A write lock will prevent users from attempting any kind of operations such as read, update or delete on the locked rows. A read lock allows others to read the lock but they will not be able to update or delete it.
pessimistic has many disadvantages, it slows down applications because all users have to wait for an entity's locks to be released, it also may introduce deadlock conditions, transactions live longer because objects are around longer due to increases that the lock will be in place for longer.
The optimistic locking is more difficult to implement but it is the most popular approach, JPA does support optimistic locking, although most applications are high-transaction systems rarely do concurrency problem occur. When a user retrieves an entity for update, a copy of the object is provided and changes are made to the copy. After the user makes some changes to the entity, he is ready to save it. The application now obtains a write lock on the object and checks whether data has been updated since the user obtained it. If there has been no update to the original data then the user can commit the copy of the entity to the database, Otherwise the application show throw an exception. The optimistic locking strategy is typically implemented by adding a column to the database table for the entity and storing either storing a version number or a timestamp to track changes, the version number approach is the preferred choice. When updating the object the version numbers are compared if they are different then the application will throw an OptimisticLockingException. There is no way to recover from an OptimisticLockingException you would have to retrieve a fresh copy of the entity and try to reapply the changes.
| @Version | @Entity |
The EntityManager provides a lock method to explicitly acquire a lock on an entity, there are two types of lock: WRITE or READ. You must have version attributes on any entity to be locked using the lock method, and the entity must be managed.
| READ lock | entityManager.lock(item, LockModeType.READ) |
| WRITE lock | entityManager.lock(item, LockModeType.WRITE) |
There are a number of issues that can cause bad performance at the persistence tier
The persistence provider will generate the SQL statements, so you must be able to know how to obtain these so that you can confirm what is being sent to the database.
You may be able to improve performance by merging two small tables, for example say you had a tabled called "billing_details" and another called "address", we will always require an address thus there is JOIN performed between the two tables. You could merge the two tables (normalize) thus the JOIN would no longer be required.
We could go the other way and break down a table, especially if most of the data in the table is not required, for an example you may have a seller table which contains columns like purchase date, manufacturing date, warranty information, picture, etc. Most of this information is not frequently used, so we generally mark these as lazy load, however some vendors have different defaults for example some vendors BLOBs fields are not lazy loaded by default. You split this table into two items and item_details and share the same primary key you could then set the fetch mode to lazy load.
Choosing the right inheritance strategy can also improve performance, there are three types of inheritance mapping (see persisting entities for more information), the single-table strategy will probably give you the best performance advantage, the reason for this is that all entities are stored in a single table and JOINs between tables are avoided.
| inheritance strategy | @Inheritance(strategy = InheritanceType.SINGLE_TABLE) |
The JPA internally uses JDBC to store and retrieve entities, most application servers today offer JDBC connection pooling which can improve performance so this pool used be size correctly and this depends on what system you have (high or low transactions), I have discussed tuning the JBoss server and sizing the connection pool.
The persistence provider executes SQL on your behalf, many SQL statements are run multiple times, many application servers provide the ability to cache SQL statements and thus can reuse them. This lowers the overhead of cursor creation as well as the parsing of SQL statements - both of which can be very time consuming.
| caching statements | <data-source> ... num-cached-statements = "200" ... </data-source> |
The other big performance impact is that making sure that SQL parameter binding is used, this means that that the SQL can be cached and used again, this is pretty much standard database requirements now days, so just make sure you bind your variables.
| Statement with no binding | Query query = em.createQuery( "SELECT c FROM Category c WHERE c.categoryName = " + categoryName ); |
| Statement with binding | Query query = em.createQuery( "SELECT c FROM Category c WHERE c.categoryName = ?1" ); query.setParameter(1, categoryName); |
Try to use named queries instead of dynamic queries were possible, named queries are prepared once and can be efficiently reused by the persistence provider, it can also be cached. Again make sure you use bind variables/parameters in your named query (see above).
If the results of your query will not be updated, then don't use a transaction (they are expensive), by default the transaction attribute for a session bean is REQUIRED, change this to NOT_SUPPORTED for read-only queries.
There are a number of things that you can do to reduce database operations, even if the persistence provider generates the query.
Choosing the right fetch type can improve performance, lazy loading leads to multiple SQL statements where as eager loading relates to a SQL JOIN statement and translates to unnecessary data, the defaults are below regarding that is used for each relationship
You can use the FETCH clause with a join
| define the loading type | SELECT u FROM User u JOIN FETCH u.billingInfo WHERE u.firstName like ?1 |
You can defer database updates until the end of the transaction, by default the flush mode for EJB 3 is auto, you can control this by using the EntityManager's flush method, excessive use of the flush method can degrade performance. You can set the flush method to COMMIT, this means that all the updates are deferred until the end of the transaction. I have gone into more detail in my EJB manipulating topic.
We discussed in manipulating entities the attribute cascadeType.REMOVE which when you remove an entity will automatically remove any associated entities, this can have a negative impact on performance, it may be better to let the database take care of this by using a cascade delete constraint on the tables, it generally gives better performance. I suggest that you play around with these options for example when set to ALL the persistence provider will try each operation (persist, merge, refresh, etc) on the target entity, this can lead to unnecessary database operations when you have several associated entities, and each of the operations is cascaded.
There probably be times when you require to make changes to multiple entities within one transaction, you retrieve a collection of entities and iterate through each one to make changes, this will of course will generate many update statements, if possible try to rewrite the query to perform the operation in one statement.
| Bad bulk statement | Query query = em.createQuery("select s from Seller s where s.createDate <= ?1"); ... List sellers = query.getResultList(); Iterator i = seller.iterator(); while (.hasNext()) { Seller seller = (seller) i.next(); seller.setStatus("GOLD"); } |
| Good bulk statement | UPDATE Seller s SET s.status = 'GOLD' WHERE s.createDate <= ?1 |
Association tables are commonly used to store unidirectional, one-to-many relationships, this is supported in EJB 3 with the @JoinTable annotation, using an association table will require extra SQL statement to manage the relationship, as well as unnecessary JOINs between the base tables and association tables.
It may be worth enabling a higher level of logging in the persistence provider, thus you can obtain the full SQL statements used, this then can be "tuning utilities" to try and get the most optimized SQL.
Like all databases unless tables are small try to avoid full table scans, try and use a WHERE clause if possible, also make sure that the DBA has created indexes on large column tables that you do not need to retrieve specific columns.
Try to use indexes for relationship fields, otherwise full table scans will happen, again liaise with the DBA to obtain the best table structure.
The last performance improvement can be to limit the number of rows retrieved (this is vendor specific), you can pass the JDBC fetch size as a vendor-specific @QueryHint in either named or dynamic queries
| QueryHint | @NamedQuery( name = "findUserWithNoItems", query = "Select distinct u from User u where u.items is empty", hints = {@QueryHint(name = "org.hibernate.fetchSize ", value = "50")} ) |
EJB3 JPA does not require persistence providers to do any type of caching, but caching helps in reducing the amount of trips to the database. Be careful though, caching does have its downside as data can become stale thus causing other performance issues. Check with your vendor but most will support caching of entities and queries, caching is best used when data does not change much (read-only), it can be broken into three levels
Transactional Cache ensures that the object from the cache is returned when the same object is requested again, for an example say you run a query requesting an item, the object is cache thus if you request the same item again it is already in memory. The other benefit of a transactional cache is that all updates to an entity are deferred to the end of the transaction, if you don't use caching the persistence provider may have to perform a number of SQL statements that are not needed or could be better performed. Transactional cache is known as the first level cache or session cache, most providers by default will have this cache enabled.
The transactional cache will demarcate a single transaction, this may be a problem if your application needs to maintain conversational state between method calls, you can avoid this situation by using extended persistence context. Only stateful session beans support extended persistence context, they allow you to keep an entity instance managed beyond a single method call and transaction boundary.
| extended persistence context | @PersistenceContext(unitName="ActionBazaar", type=PersistenceContextType.EXTENDED) EntityManager em; |
However there are limitations related to the propagation of the extended persistence context that relate to injection other stateless session beans inside another stateful bean, see EJB 3 integration for more details.
The transactional and persistence context caching mechanisms can only be used with a single client and cannot be shared, you will get a real boost when entity instances in the cache are shared by multiple clients, thus reducing trips to the database for all of them. This is called the PersistenceUnit cache because entities are scoped in a persistence unit, this is also known as the second-level cache. You need to configure an external cache provider to take advantage of this second-level or session factory level cache.
| Persistence Unit cache using topLink | @NamedQuery( |
Understanding your applications and checking your caching strategy usually makes sense for your applications, caching is best for entities that do not change frequently or are read-only, and be careful of stale data especially if other external applications update the database as well. Cache mechanisms are different from vendor to vendor so make sure you read what is available for you specific application server. I have talked about caching in JBoss in my JBoss 5 clustering services topic. The best tactic is to stress test the application with and without caching enabled, this will be the best way to decide if you want to use caching.
There are a number of ways to improve the application by tuning EJB 3 components, I have a table below detailing the most beneficial
Session Beans |
|
| Local v Remote | @Remote uses expensive RMI calls requiring copy-by-value semantics, even if the client is in the same JVM, so try to @Local where possible. |
| Stateful session beans | Stateless session beans perform much better than stateful beans, unless you need to maintain state use stateless beans. |
| Session Facade pattern | Try to void building fine-grained EJBs by following the Session facade design pattern, check to see you can consolidate several EJB methods into a single coarse-grained EJB method. Reducing multiple method calls to a single call will improve performance of your EJB application. |
| Transaction attribute settings | Transactions are expensive, so make sure that you need one. If you are using CMT the container will start a transaction for you because the default transaction attribute is Required. Explicitly disable transactions when you do not require one @TransactionAttribute(TransactionAttributeType.NOT_SUPPORTED) <method> |
| Optimize the stateless bean pool | Make sure you have enough bean resources, I have talked about this in my JBoss tuning section. |
| Stateful bean cache and passivation | Unnecessary passivation will slow the performance, check the containers default values regarding passivation, I have talked about passivation in the below topics, but check with your containers documentation |
| @Remove annotation | Use @Remove to destroy a stateful session bean, not removing these beans may lead to more passivation/activation problems. Although you can set timeout values, you should use the @Remove annotation. |
| Control serialization by making variables transient | Cut down on serializing and deserializing as it is an expensive process, make a object transient and the container will skip that object during passivation/activation. |
Message-Driven Beans (MDB) |
|
| Initializing resources | Like with stateful session beans, MDB are also pooled, see JBoss tuning for more details on pooling. |
| Sizing the pool | see JBoss tuning for more details on pooling. |
Clustering is an advanced subject and can become complex, I point you to my JBoss clustering documentation which can improve performance, but from my own view I think that this solution is more about high availability and salability than performance, clustering is not a subject to be taken lightly.