Java Persistence API (JPA) is about managing and persisting data generally to a database, it basically maps objects to database table using Object Relational Mapping (ORM), using JPA you can carry out the CRUD operations (Create, Read, Update and Delete). JPA is actually a specification and several implementations are available, popular implementations are Hibernate, EclipseLink and Apache OpenJPA. So why use a API this allows you to swap the API at a later date if you so wish and use another API but still allows you to use Hibernate to access the database.
The JPA API gives you the methods that then uses Hibernate to manage and persist data and thus makes coding much easier.

Back in the first section we saw how Hibernate uses transactions, below is the equivalent using Java Persistence API, you also use a persistence.xml file, when using Spring Boot most of this boiler code goes away but its still good knowledge to have.
| Introduction | public class HelloWorldClient {
public static void main(String[] args) {
EntityManagerFactory emf = Persistence.createEntityManagerFactory("hello-world");
EntityManager em = emf.createEntityManager();
EntityTransaction txn = em.getTransaction();
try {
txn.begin();
Message msg= new Message("Hello World with Hibernate as JPA Provider");
em.persist(msg);
txn.commit();
} catch(Exception e) {
if(txn != null) { txn.rollback(); }
e.printStackTrace();
} finally {
if(em != null) { em.close(); }
}
}
} |
| persistence.xml | <?xml version="1.0" encoding="UTF-8"?>
<persistence xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd"
version="2.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="hello-world" transaction-type="RESOURCE_LOCAL">
<properties>
<!-- Database connection settings -->
<property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver" />
<property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/hello-world" />
<property name="javax.persistence.jdbc.user" value="root" />
<property name="javax.persistence.jdbc.password" value="password" />
<!-- SQL dialect -->
<property name="hibernate.dialect" value="org.hibernate.dialect.MySQLDialect" />
<!-- Create/update tables automatically using mapping metadata -->
<property name="hibernate.hbm2ddl.auto" value="update" />
<!-- Pretty print the SQL in the log file and console -->
<property name="hibernate.format_sql" value="true" />
</properties>
</persistence-unit>
</persistence> |
The object lifecycle is as per below, it can be in a number of states, and various methods can be used to change the state.
- Transient - object is created using the new operator but not yet persistent, also the method delete() is used
- Persistent - the object is now associated with the entity manager (persistence context, see below), it has a database identity, methods like save(), persist() saveOrUpdate() are used
- Detached - when the EntityManager is closed the object becomes detached, so if you try to change object it will have no affect in the database in a detached state. You can use the merge(), update() methods to put into a persistence state and thus dirty checking will take place.

What is a persistence context, its a first-level cache (memory) and it has its own non-shared database connection, the persistence context checks if an object has got dirty (modified) and thus would update the changes if the transaction gets comitted (also known as automatic dirty checking). To note that each EntityManager has a persistence context and thus a hibernate session is also a persistence context. It is not easy to see or modify the persistence context outside of Hibernate, this cache can improve performance as if the object is already in the cache the SQL statement will not be executed to the database but the object retrieved from the persistence context. One point to note is that Hibernate does not cache between EntityManagers you would need a second-level cache for this which I will discuss later, also only one copy of the object can exist in the persistence context.

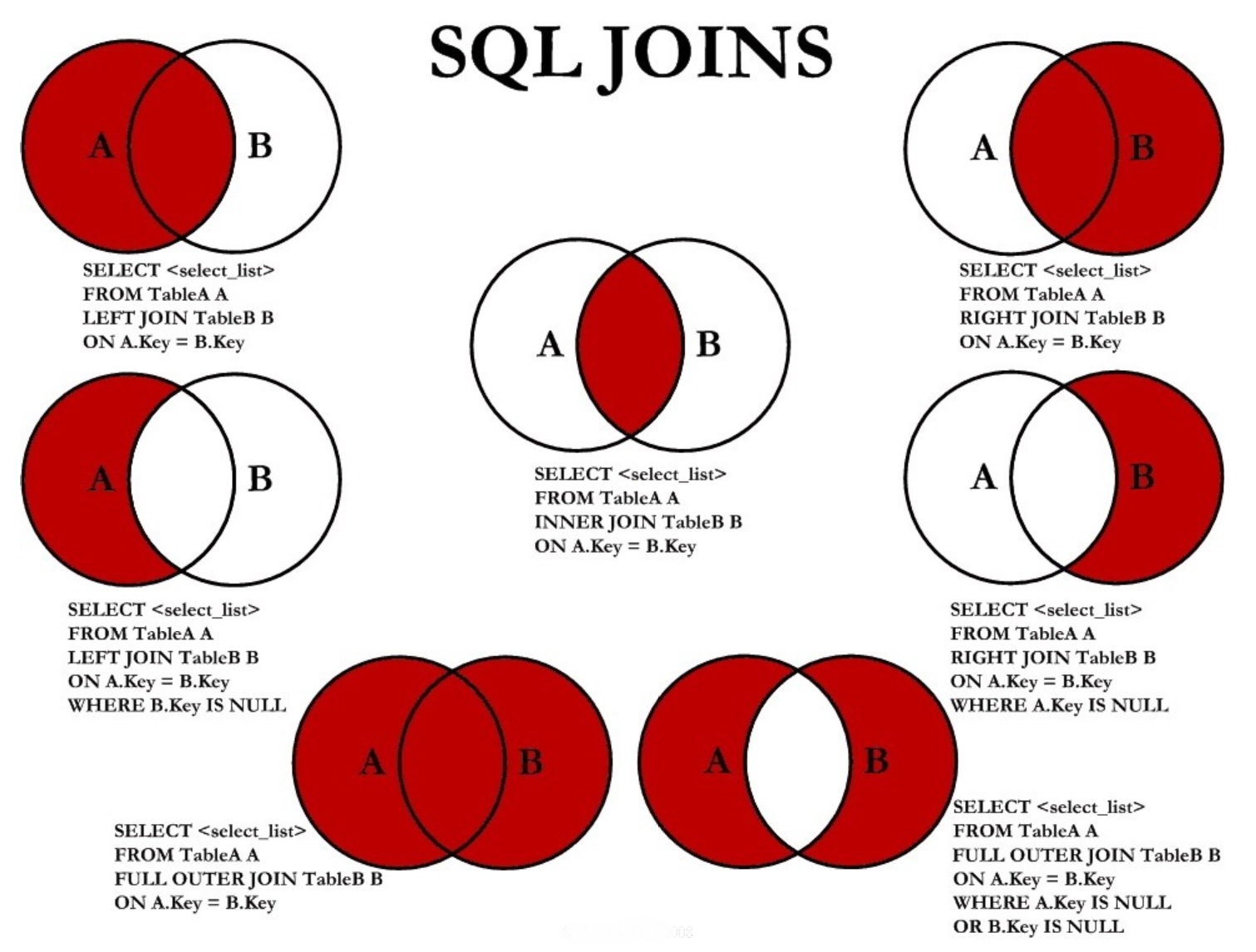
It is good to have a little understanding of SQL joins, the most commonly used are the inner join and the left outer join.
When fetching/loading data there are two classifications
- Eager - is a design pattern in which data initialization occurs on the spot
- Lazy - is a design pattern which is used to defer initialization of an object as long as it's possible
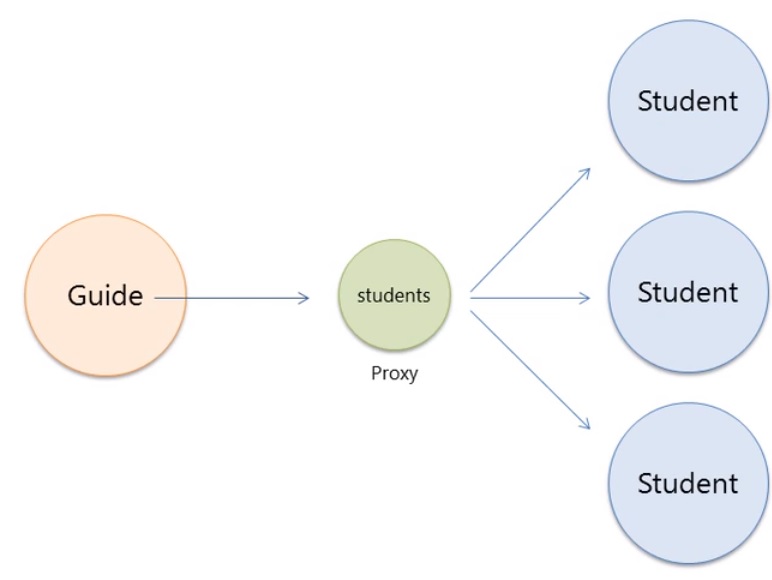
When Hibernates fetches data does it fetch the other reference objects of that entity, to determine this you can view the SQL code that is run, for lazy fetching Hibernate will defer as long as possible any retrieval of data until its needed, thus reference objets unless it is being used won't be loaded (no SQL to retrieve the data). What Hibernate uses for the data that is not retrieved is a proxy (lightweight), so in the below diagram the Guide object uses a proxy student object until the student data is required. This is a big improvement inperformance as if the object graph is very big then lots of unnecessary data would be retrieved (less memory, less data over network from database).
- @OneToMany and @ManyToMany - by default are lazily fetched
- @OneToOne and @ManyToOne - by default are Eagerly fetched
If you get the error message failed to lazily initialize a collection ..... could not initialize proxy, no session this generally mean that the EntityManager has been closed and you are trying to access data that has not been retrieved (its a proxy object).
You can override the lazy fetching by using the fetch=FetchType.EAGER if you know that you will need the reference data, in this case the students. You also have the option fetch=FetchType.LAZY to make something fetch lazily.
| EAGER fetching | @OneToMany(mappedBy="guide", cascade={CascadeType.PERSIST}, fetch=FetchType.EAGER)
private Set |
I have already covered equals and hashCode in my Java Reference section, and the same principles apply here as well.
When we retrieve data (or update) we are using something called Java Persistence Query Language (JPQL), there are also other query languages like Hibernate Query Language (HQL), these automatically generates the SQL code to retrieve the data, one thing to note is that JPQL is case-senitive but the database is not. Don't get to deep into this as Spring Boot makes it very easy when querying but below is just to show how you can query using JPA directly (for old applications). Spring Boot you get many methods out of the box like FindAll(Sort) and you can use its query creation mechanism so you could use findByEmailAddressAndLastname()
| Querying Entities | Query query = em.createQuery("select guide from Guide guide");
List<Guide> guides = query.getResultList();
|
| Dynamic Queries | String name = "Paul Valle";
Query query = em.createQuery("select guide from Guide guide where guide.name = '" + name + "'");
Guide guide = (Guide) query.getSingleResult(); |
| Wildcard Queries | Query query = em.createQuery("select guide from Guide guide where guide.name like 'm%'");
List |
| Named Queries (also using chaining) | List<Guide> guides = em.createNamedQuery("findByGuide")
.setParameter("name", "Mike Lawson")
.getResultList(); |
| Using JOIN queries | Query query = em.createQuery("select student from Student student join student.guide guide");
List<Student> students = query.getResultList(); |
You can use inheritance mapping, you use a discriminator to separate the data into separate classes, the discriminator basically tells Hibernate what types of data the row is hold, in this example Cat or Dog.
- SINGLE_TABLE - the entities from different classes with a common ancestor are placed in a single table , each class has its table (animal has the discriminator, cat and dog) this is good for ploymorphic (no joins) but all subclasses must not have not-null constraints, also good for derived classes (Dog or Cat)
- JOINED - each class has its table (animal, cat and dog) and querying a subclass entity requires joining the tables, uses foreign keys to join the tables, poorer performance than single_table but you can have not-null constraints.
- TABLE_PER_CLASS - all the properties of a class, are in its table, there is no animal table, so no join is required, it also uses a single hibernate_sequences table for the id's of both tables because each table does not reference each other a ploymorphic query uses a select ... UNION sql query on both tables (cat and dog) to join all the data together.
| Introduction | @Entity
@Inheritance(strategy=InheritanceType.SINGLE_TABLE)
public abstract class Animal {
@Id
@GeneratedValue(strategy=GenerationType.AUTO)
//@GeneratedValue(strategy=GenerationType.TABLE) // to be used when using TABLE_PER_CLASS strategy
private Long id;
//@Column(nullable=false) // cannot be used when using SINGLE_TABLE strategy
private String name;
} |
| Cat class | @Entity
public class Cat extends Animal {
@Override
public String makeNoise() {
return "meow meow..";
}
} |
| Dog class | @Entity
public class Dog extends Animal {
@Override
public String makeNoise() {
return "woof woof..";
}
} |
| Queries | List<Dog> dogs =em.createQuery("select dog from Dog dog").getResultList()
List<Cat> cats =em.createQuery("select cat from Cat cat").getResultList();
// Polymorphic Query (both Dog and Cat)
Query query = em.createQuery("select animal from Animal animal");
List<Animal> animals = query.getResultList(); |
N + 1 problem is a performance issue in Object Relational Mapping that fires multiple select queries (N+1 to be exact, where N= number of records in table) in database for a single select query at the application layer. There are times that Eagerly fetch retrieves more data that it should and thus multiple additional SQL queries are executed to retrieve this data, so we end up looking like the diagram below, you have one select statement for the parent then N selects for all the children (N + 1).
Depending on the issue to solve this issue we can either change the fetch type from EAGER to LAZY and thus a proxy will be loaded instead, or we can change the query to use a LEFT JOIN FETCH. There is also another soltuino which is batch fetching which is in the next section.
| Use Lazy fetch | @Entity
public class Pet {
@ManyToOne(fetch=FetchType.LAZY, cascade={CascadeType.PERSIST})
@JoinColumn(name="owner_id")
private Owner owner;
....
} |
| Rewrite Query (left join fetch) | public class Client {
Query query = em.createQuery("select pet from Pet pet left join fetch pet.owner");
List<Pets> pets = query.getResultList();
.....
}
Note: this probably won't work then there is a huge number of students and thus selects statements, then use above solution. |
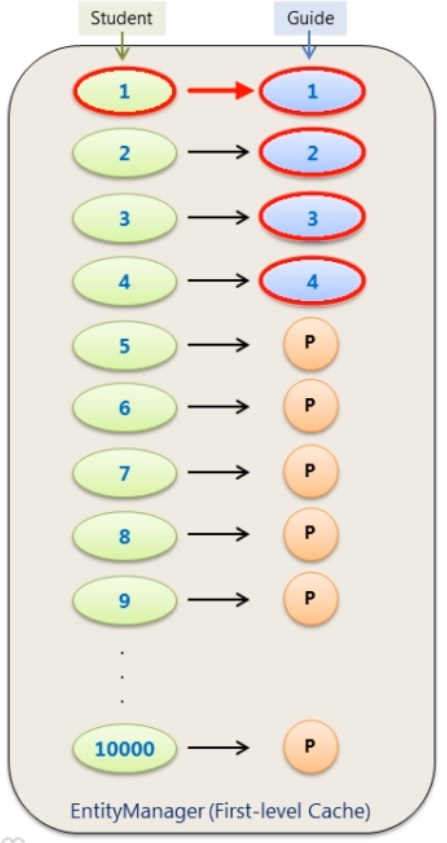
Batch fetching (Hibernate feature not JPA) is used when there are many select statements in regards to a N + 1 problem, when lazy loading we know that proxy objects are used however we can use a @BatchSize annotation to pretch the proxy objects, you can optimize the batchsize to load just the required amount each time. Son in the diagram below the first select a batch of 4 guide objects are load then on the 5th Student another batch of 4 guide objects are prefetched, etc. so if you had 10,000 students you divide it buy 4 and thus its takes 2500 (child) + 1 (parent) select statements instead of 10,000. This is a inbetween solution than the two above in the N + 1 section.
| BatchSize example | @Entity
@BatchSize(size=4) // prefetch lazy objects
public class Guide {
.....
} |
We can merge detach objects using the merge() method, also the cascade type MERGE comes into play when we want to also merge assoicated objects that are part of a parent object. One point to note is that you must keep the transactions as short as possible especially in a multi-user environment so that others can also make changes to possible the same objects. You can use extended persistence context this is where you don't deatch the object but perform all the changes in one transaction but this means others cannot make changes.
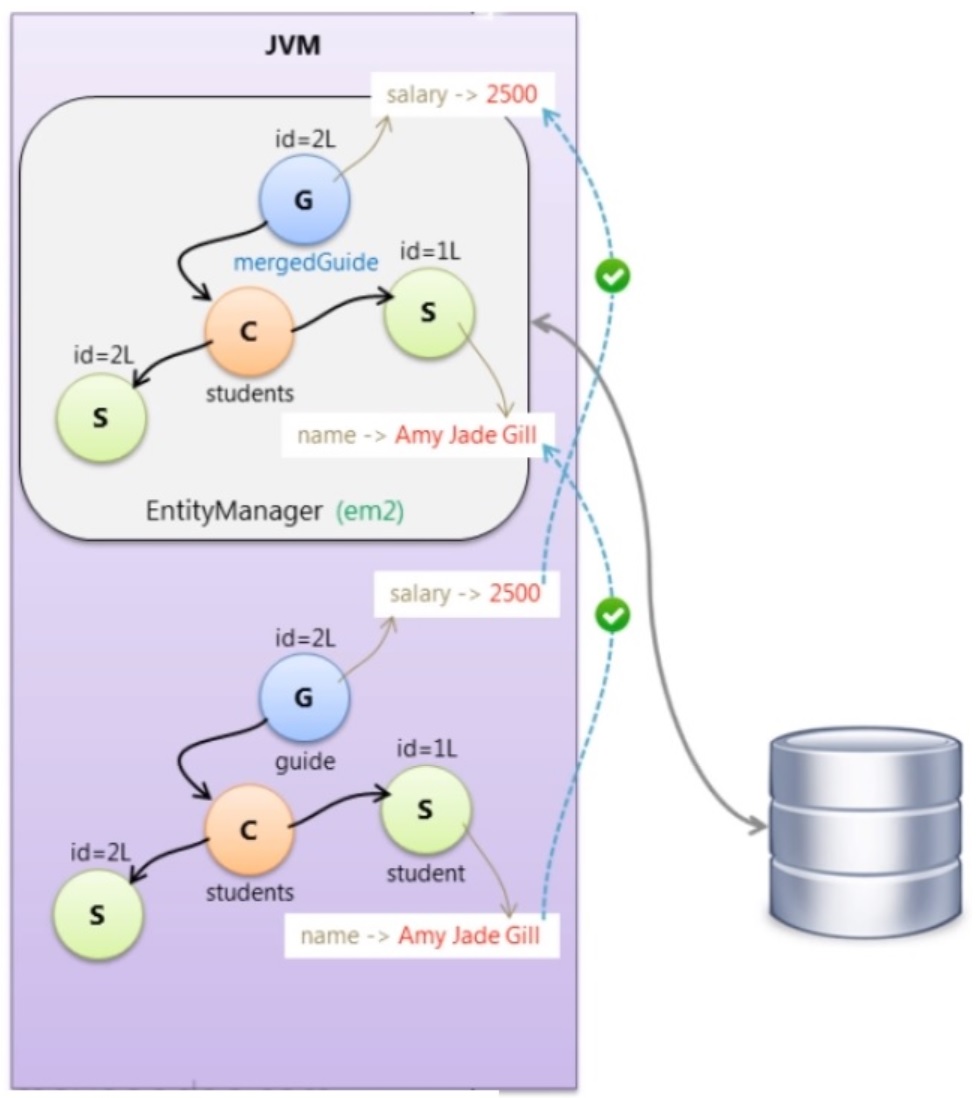
| Introduction | EntityManagerFactory emf = Persistence.createEntityManagerFactory("hello-world");
EntityManager em1 = emf.createEntityManager();
em1.getTransaction().begin();
Guide guide = em1.find(Guide.class, 2L); // Guide is loaded into the persistence context
Set<Student> students = guide.getStudents(); // proxies are created but no data is retrieved from the database
int numOfStudents = students.size(); // data is retrieved from the database
Student student = null;
for(Student nextStudent: students) {
if(nextStudent.getId() == 2L) {
student = nextStudent;
}
}
em1.getTransaction().commit(); // data is persisted to the database
em1.close(); // objects are detached, no lonmger in the persistence context
guide.setSalary(2500); // data is changed in the detached objects
student.setName("Amy Jade Gill");
EntityManager em2 = emf.createEntityManager(); // create new persistence context
em2.getTransaction().begin();
@SuppressWarnings("unused")
Guide mergedGuide = em2.merge(guide); // data is retrieved from the database into the peristence context
// copy the detach data into the persistence context and merge it
em2.getTransaction().commit(); // commit the changes to the database (automatic dirty checking)
em2.close(); |
| Guide class | // use cascade to MERGE associated students
@OneToMany(mappedBy = "guide", cascade={CascadeType.MERGE})
private Set<Student> students = new HashSet<Student>(); |
Optimistic Locking and Versioning
This related to detached objects and how two users want to modify the same data, this scenario can result in lost updates, we can use the @Version annotation that adds a column to the table called version, any updates increase this version number, Hibernates uses this version to check that lost updates are not lost as an OptimisticLockException is thrown if the version number is in-correct when updating. Versioning is classed as optimistic locking we don't lock the database, locking the database is called pessimistic locking.
| Version example | @Version private Integer version; |
| LockModeType example | Query query = em.createQuery("select guide.name, guide.salary from Guide as guide")
.setLockMode(LockModeType.PESSIMISTIC_READ); // also have PESSIMISTIC_WRITE
List<Guide> guides = query.getResultList();
Note: you are using database locks |
An Isolation level defines the extent to which a transaction is visible to other transactions, the lesser isolation the better performance but lesser data integrity.
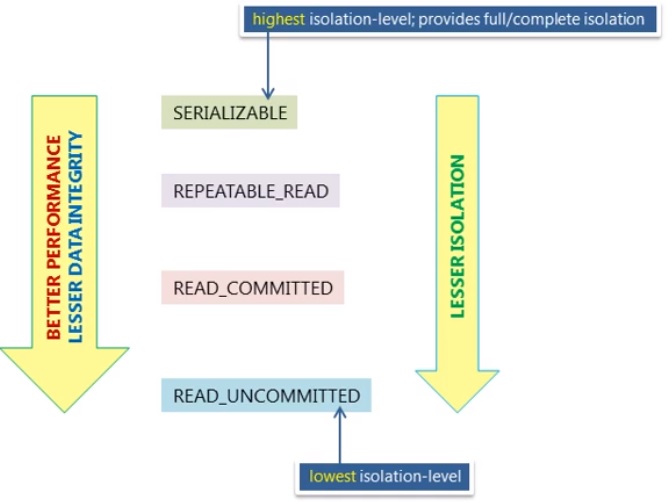
| READ UNCOMMITTED | This setting allows all transactions to see all uncommitted changes, whether in the own transaction or in another transaction, these are unknown as dirty reads, the data is said to be dirty because the changes are not permanent. This setting is not ACID compliant and is discouraged as it will make you system non-transactional. |
| READ COMMITTED | Only data changed by committed transactions are visible to other transactions, however within a transaction, dirty data can still be read. This means identical queries within a transaction can return different results. This setting is the default option in both Oracle and SQL Server. |
| REPEATABLE READ | All reads within the transaction show the same data values, even if a second transaction has committed a data change while the first transaction was still running. For example if a transaction starts, reads a row, waits 60 seconds and then reads the same row again both data reads will be the same even if someone else's changes the row with those 60 seconds, however any transactions started after the commit will see the new data. This setting is the default option for MySQL |
| SERIALIZABLE | Data reads are implicitly run with a read lock (the lock in share mode), other transactions can read the data but no transactions can update this data until the read locks are release, this of course impacts concurrency. |
You can change the Hibernate isolation level as per below
| Change the isolation level in Hibernate (peristence.xml file) | <!-- 1 = READ UNCOMMITED, 2 = READ COMMITTED, 4 REPEATABLE READ --> <property name="hibernate.connection.isolation" value="2" /> |
A second level cache (shared cache, L2 cache, etc) is optional but can improve performance, as we know that EntityManagers do not share objects as they have there own persistence context (memory area), a second level cache uses the EntityManagerFactory scope and thus all EntityManagers will have access. Data is stored as key/value pairs not as object as we have seen, as per the diagram below:

One point to make is that some cache providers you might need to configure a link reference between the caches that are associated with each other, otherwise additional select statements may happen, in the below diagram additional configuration has been used to link the guide and the student caches, remember the cache is a key/value pairs solution it does not use objects (so no object graph exists).
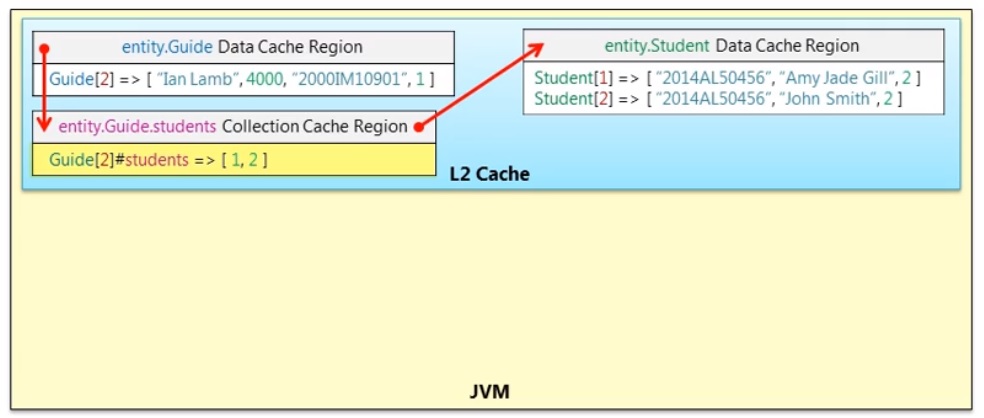
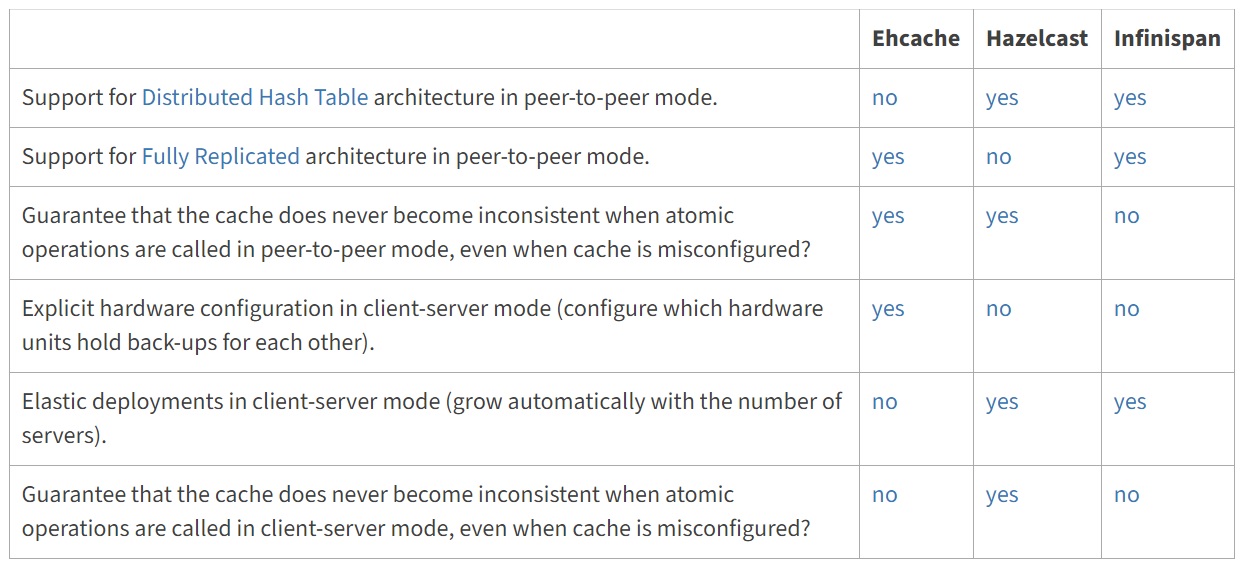
You can use Ehcache (single JVM), Infinispan, TreeCache (JBoss - Multiple JVM's) or Hazelcast as some of the cache providers each of which has pros and cons and what your requirements are (Standalone JVM, Clustering, Elastic Computing, etc)
I am going to show how to setup a second level cache in my Spring Boot section.