High Availability and Clustering
When you have very critical systems that require to be online 24x7 then you need a HA solution (High Availability), you have to weigh up the risk associated with downtime against the cost of a solution. HA solutions are not cheap and they are not easy to manage. HA solutions need to be thoroughly tested as it may not be tested in the real world for months. I had a solution that run for almost a year before a hardware failure caused a failover, this is when your testing before hand comes into play.
As I said before HA comes with a price, and there are a number of HA technologies
Every company should plan for unplanned outages, this costs virtually nothing, knowing what to do in a DR situation is half the battle, in many companies people make excuses not to design a DR plan (it costs to much, we don't have the redundant hardware,etc). You cannot make these assumptions until you design a DR plan, the plan will highlight the risks and the costs that go with that risk, then you can make the decision on what you can and cannot afford, there is no excuse not to create DR plan.
Sometimes in large corporations you will hear the phrase five nines, this phrases means the availability of a system and what downtime (approx) is allowed, the table below highlights the uptime a system requires in order to achieve the five nines
| % uptime | % Downtime | Downtime per year | Downtime per week |
| 98 | 2 | 7.3 days | 3 hours 22 minutes |
| 99 | 1 | 3.65 days | 1 hour 41 minutes |
| 99.8 | 0.2 | 17 hours 30 minutes | 20 minutes |
| 99.9 | 0.1 | 8 hours 45 minutes | 10 minutes |
| 99.99 | 0.01 | 52.5 minutes | 1 minute |
| 99.999 (five nines) | 0.001 | 5.25 minutes | 6 seconds |
To achieve the five nines your system is only allowed 5.25 minutes per year or 6 seconds per week, in some HA designs it may take 6 seconds to failover.
When looking for a solution you should try and build redundancy into your plan, this is the first step to a HA solution, for example
You are trying to eliminate as many Single Point Of Failures (SPOF's) as you can without increasing the costs. Most hardware today will have these redundancy features built in, but its up to you to make use of them.
HA comes in three/four favors
| No-failover | This option usually uses the already built-in redundancy, failed disks and PSU can be replaced online, but if a major hardware was to fail then a system outage is unavoidable, the system will remain down until it is fixed. This solution can be perfectly acceptable in some environments but at what price to the business, even in today's market QA/DEV systems cost money when not running, i am sure that your developers are quite happy to take the day off paid while you fix the system |
| Cluster | This is the jewel in the HA world, a cluster can be configure in a variety of favors, from minimal downtime while services are moved to a good nodes, to virtual zero downtime. However a cluster solution does come with a heavy price tag, hardware, configuration and maintaining a cluster is expensive but if you business loses vast amounts of money if you system is down, then its worth it. |
| Cold failover | Many smaller companies use this solution, basically you have a additional server ready to take over a number of servers if one where to fail. I have used this technique myself, i create a number of scripts that can turn a cold standby server into any number of servers, if the original server is going to have a prolonged outage. The problem with this solution is there is going to be downtime, especially if it takes a long time to get the standby server up to the same point in time as the failed server. The advantage of this solution is that one additional server could cover a number of servers, even if it slight under powered to the original server, as long as it keeps the service running. |
| Hot failover | Many applications offer hot-standby servers, these servers are running along side the live system, data is applied to the hot-standby server periodically to keep it up to date, thus in a failover situation the server is almost ready to go. The problem with this system is costs and manageability, also one server is usually dedicated to one application, thus you may have to have many hot-standby servers. The advantage is that downtime is kept to a minimum, but there will be some downtime, generally the time it take to get the hot-standby server up todate, for example applying the last set of logs to a database. |
Here is a summary table that shows the most command aspects of cold failover versus hot failover
| Aspects | Cold Failover | Hot Failover |
| Scalability/number of nodes | Scalable limited to the capacity of a single node | As nodes can be added on demand, it provides infinite scalability. High number of nodes supported. |
| User interruption | Required up to a minimal extent. The failover operation can be scripted or automated to a certain extent | Not required, failover is automatic |
| Transparent failover of applications | Not Possible | Transparent application failover will be available where sessions can be transferred to another node without user interruption |
| Load Balancing | Not possible, only one server will be used | Incoming load can be balanced between both nodes |
| Usage of resources | Only one server at a time, the other server will be kept idle | Both the servers will be used |
| Failover time | More than minutes as the other system must be cold started | Less than a minute, typically in a few seconds. |
I have discussed clustering in my Tomcat and JBoss topics, so I will only touch on the subject lightly here. A cluster is a group of two or more interconnected nodes, that provide a service. The cluster provides a high level of fault tolerance, if a node were to become unavailable within the cluster the services are moved/restored to another working node, thus the end user should never know that a fault occurred.
Clusters can be setup to use a single node in the cluster or to load balance between the nodes, but the main object is to keep the service running, hence why you pay top dollar for this. One advantage of a cluster is that it is very scalable because additional nodes can be added or taken away (a node may need to be patched) without interrupting the service.
Clustering has come a long way, there are now three types of clustering architecture
| Shared nothing | each node within the cluster is independent, they share nothing. An example of this may be web servers, you a have number of nodes within the cluster supplying the same web service. The content will be static thus there is no need to share disks, etc. |
| Shared disk only | each node will be attached or have access to the same set of disks. These disks will contain the data that is required by the service. One node will control the application and the disk and in the event of a that node fails, the other node will take control of both the application and the data. This means that one node will have to be on standby setting idle waiting to take over if required to do so. A typical traditional Veritas Cluster and Sun Cluster would fit the bill here. |
| Shared everything | again all nodes will be attached or have access to the same set of disks, but this time each node can read/write to the disks concurrently. Normally there will be a piece of software that controls the reading and writing to the disks ensuring data integrity. To achieve this a cluster-wide filesystem is introduced, so that all nodes view the filesystem identically, the software then coordinates the sharing and updating of files, records and databases. Oracle RAC and IBM HACMP would be good examples of this type of cluster |
The first Oracle cluster database was release with Oracle 6 for the digital VAX, this was the first cluster database on the market. With Oracle 6.2 Oracle Parallel Server (OPS) was born, which used Oracle's own DLM (Distributed Lock Manager). Oracle 7 used vendor-supplied clusterware but this was complex to setup and manage, Oracle 8 introduce a general lock manager and this was a direction for Oracle to create its own clusterware product. Oracle's lock manager is integrated with Oracle code with an additional layer called OSD (Operating System Dependent), this was soon integrated within the kernel and become known as IDLM (Integrated Distributed Lock Manager) in later Oracle versions. Oracle Real Application Clusters 9i (Oracle RAC) used the same IDLM and relied on external clusterware software (Sun Cluster, Veritas Cluster, etc).
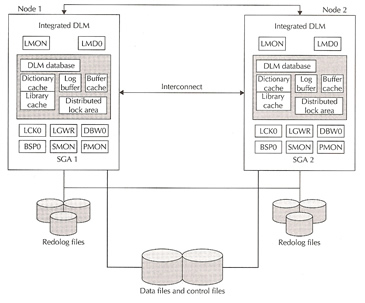
Oracle Parallel Server Architecture
A Oracle parallel database consists of two or more nodes that own Oracle instances and share a disk array. Each node has its own SGA and its own redo logs, but the data files and control files are all shared to all instances. All data and controls are concurrently read and written by all instances, redo logs files on the other hand can be read by any instance but only written by the owning instance. Each instance has its own set of background processes.
The components of a OPS database are
The Cluster Group Services (CGS) has some OSD components (node monitor interface) and the rest is built in the kernel. CGS has a key repository used by the DLM for communication and network related activities. This layer provides the following
The DLM is a integral part of OPS and the RAC stack. In older versions the DLM API module had to rely on external OS routines to check the status of a lock, this was done using UNIX sockets and pipes. With the new IDLM the data is in the SGA of each instance and requires only a serialized lookup using latches and/or enqueues and may require global coordination, the algorithm for which was built directly into the Oracle kernel. The IDLM job is to track every lock granted to a resource, memory structures required by the DLM are allocated out of the shared pool. The design of the DLM is such it can survive nodes failures in all but one node of the cluster.
A user must require a lock before it can operate on any resource, the Parallel Cache Management (PCM) coordinates and maintains data blocks exists within each data buffer cache (of an instance) so that data viewed or requested by users is never inconsistent or incoherent. The PCM ensures that only one instance in a cluster can modify a block at any given time, other instances have to wait until the lock is released.
DLM maintains information about all locks on a given resource, the DLM nominates one node to manage all relevant lock information for a resource, this node is referred to as the master node, lock mastering is distributed among all nodes. Using the IPC layer the DLM permits it to share the load of mastering resources, which means that a user can lock a resource on one node but actually end up communicating with the processes on another node.
In OPS 8i Oracle introduced Cache Fusion Stage 1, this introduced a new background process called the Block Server Process (BSP). The BSP main roles was to ship consistent read (CR) version(s) of a block(s) across an instance in a read/write contention scenario, this shipping is performed over a high speed interconnect. Cache Fusion Stage 2 in Oracle 9i and 10g, addresses some of the issues with Stage 1, in which both types of blocks (CR and CUR) can be transferred using the interconnect. Since 8i the introduction of the GV$ views meant that a DBA could view cluster-wide database and other statistics sitting on any node/instance of the cluster.
The limitations of OPS are
Oracle RAC addresses the limitation in OPS by extending Cache Fusion, and the dynamic lock mastering. Oracle 10g RAC also comes with its own integrated clusterware and storage management framework, removing all dependencies of a third-party clusterware product. The latest Oracle RAC offers
| Menu | Next |