High Availability (HA)
VMware's high availability has a simple goal, if a ESXi server crashes all the VM's running on that server do as well, the other ESXi servers within the cluster will detect this and move the VM's onto the remain ESXi servers, once the failed ESXi server has been repaired and is back online, if DRS is enabled the cluster will be rebalanced if DRS has been set to automatic. The features regarding HA in are
- Existing advanced options now available for the GUI
- New advanced options to control memory and CPU alerts
- Three different methods to indicate how to measure load on the cluster
Normally in a cluster you have a redundancy of +1 or more, for example if you need say five ESXi servers to support your environment, then you should have six ESXi servers within the cluster, the additional ESXi server would help during a server crash or if you need to update/repair a server, thus there would be no degradation of your services.
If you have previous experience of clusters you would have heard of split-brain, basically this means that either one of more ESXi server become orphaned from the cluster due to network issues, this is also know as the isolated host. The problem with the split is that each part thinks it is the real cluster, VMware's default behavior is that the isolated host powers off all its VM's, thus the locks on the VM's files are then available for other ESXi servers to use. So how does a ESXi server know that its isolated, you could configure a default gateway and thus if it cannot get to this gateway then there is a problem, you can also use an alternative IP device as a ping source. Try and make sure that you have redundancy built into your Service Console network (multiple NIC's or even a second Service Console).
With version 4 you must have at least one management port enabled for HA for the HA agent to start and not produce any error messages, try and setup this port on the most reliable network.
To configure a management port follow below
| Management port | Confirm that you have setup the management network for each of the ESXi servers that you wish to use HA
|

Now that you have a Management Port Group setup you are ready to configure HA, you should have a cluster already setup (if not then see my Clustering and DRS section), select the cluster and the configure tab and then vSphere Availibility. When you first look at HA there will be a number of alerts indicating that some configuration needs to be completed.
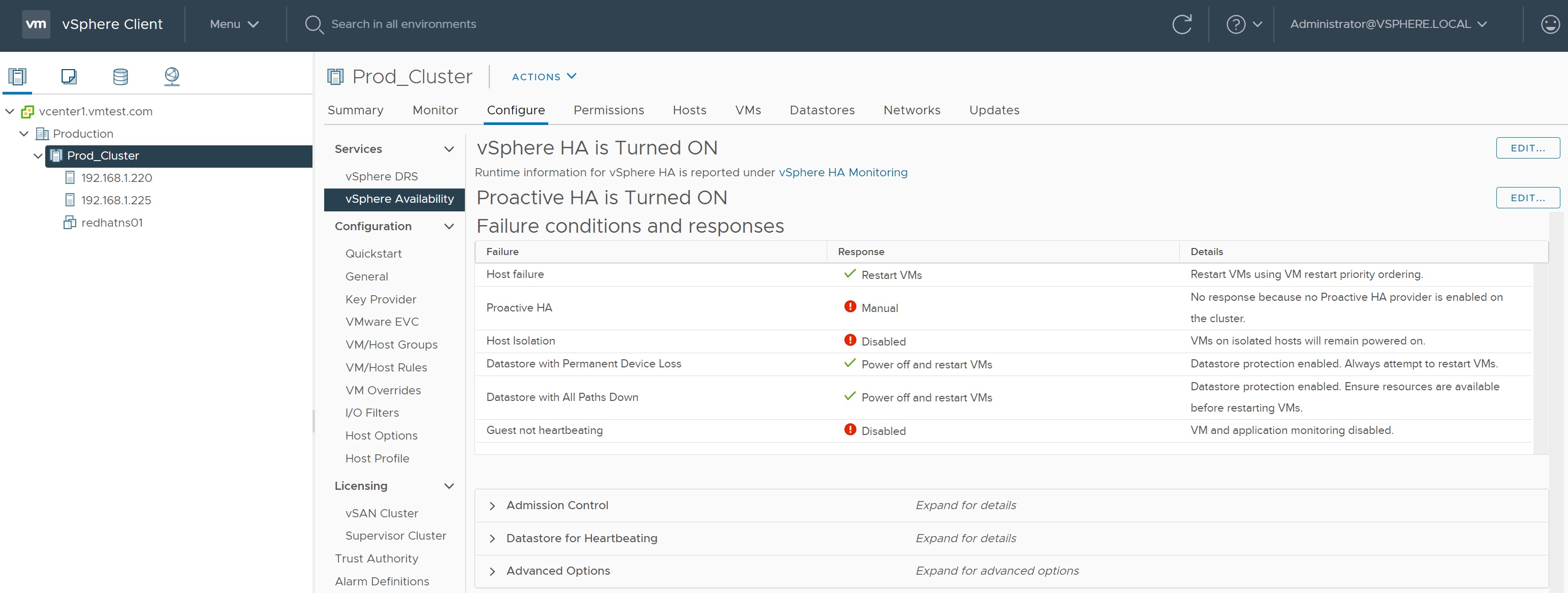
There are two HA configurations that you can setup normal HA and a Proactive HA, we will start with the normal HA, the first screen deals with Failures and Responses, there are a number of conditions that you can set, what happens to a Host Failure (ESXi failure), what to do with a Host that is isolated, VM component protections such as Permanent Device Loss (PDL) and All-Paths-Down (APD) and VM monitoring.
Permanent Device Loss (PDL):
- A datastore is shown as unavailable in the Storage view
- A storage adapter indicates the Operational State of the device as Lost Communication
- A datastore is shown as unavailable in the Storage view
- A storage adapter indicates the Operational State of the device as Dead or Error

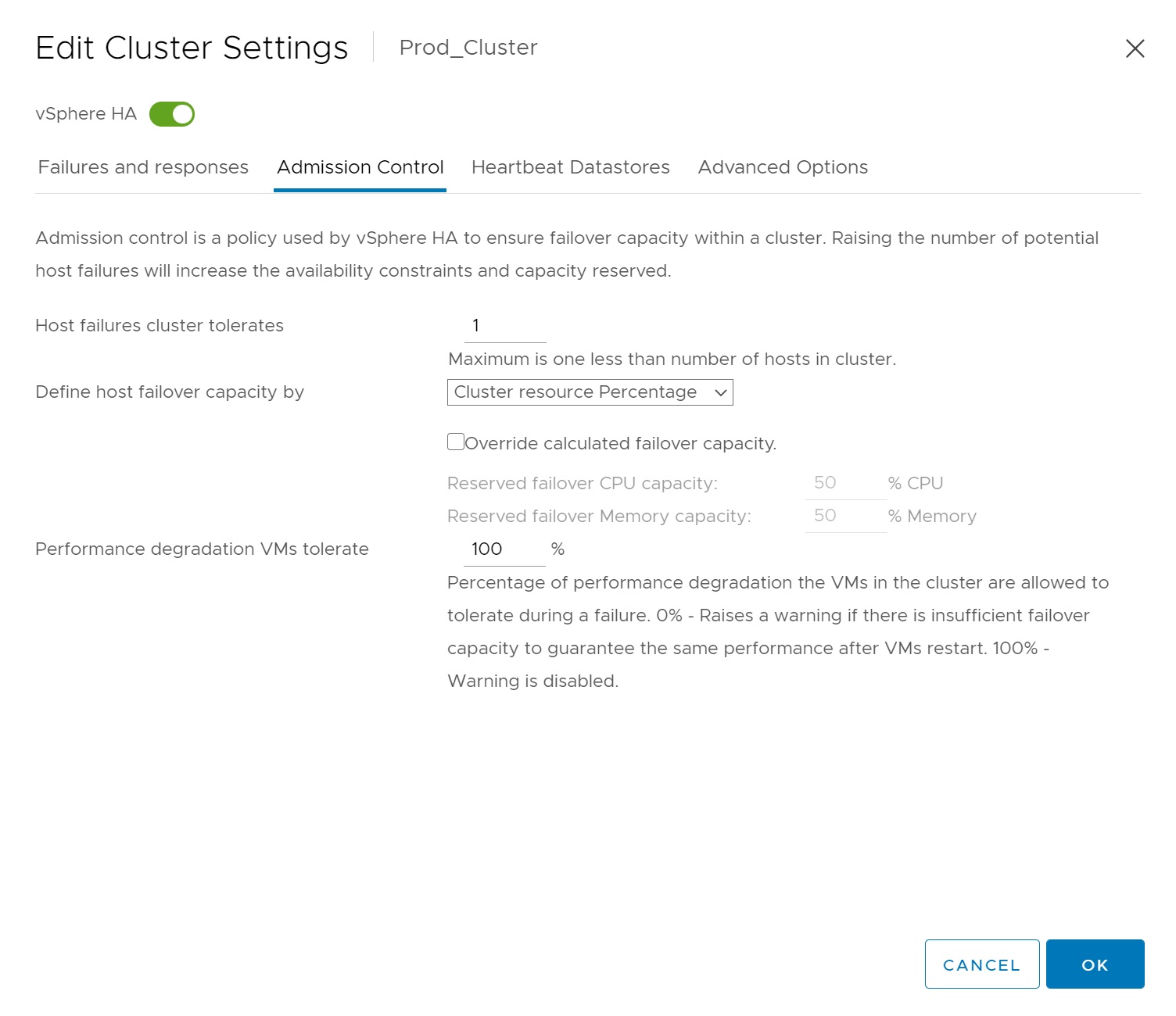
The next section regarding Admission Control is a policy that ensures failover capacity within a cluster, for example how many ESXi servers the cluster can tolerate, or the capacity loss of a ESXi server, etc. Most of the options are self explaining and are determined by how many ESXi servers are within the cluster.
Next we come to HeartBeat datastores, the datastores are used to monitor the ESXi servers and VM's when a network issue occurs, this helps with split brains within a cluster where ESXi servers become deattached from the cluster. Two datastores are used and you have a few options to either automatically select them or to specifically specify which ones to use.

Lastly we have an advanced options which are paramneters you can set for the cluster, these are areas where VMWare many ask you to add entries that are beyond the normal configuration.

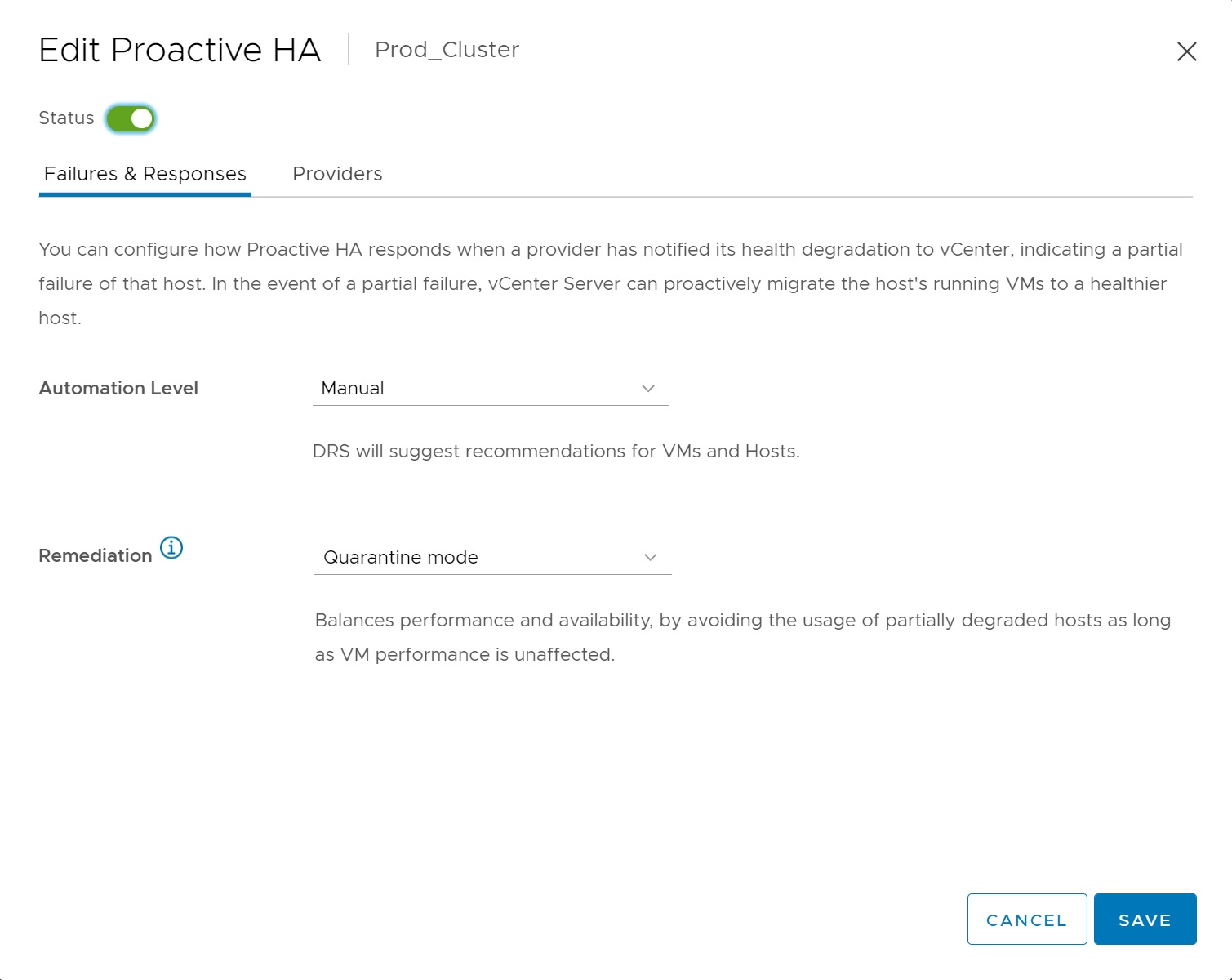
Next we have the Proactive HA seection, this allows the vCenter a more proactive approach to handling issues within the cluster, the first screen allows you to either take a manual approach or let VMWare handle the situation thus automatically move VM's to surviving ESXi servers within the cluster. The remediation determines what happens to partially degraded hosts
- Quarantine mode for all failures - Balances performance and availability, by avoiding the usage of partially degraded hosts provided that virtual machine performance is unaffected.
- Quarantine mode for moderate and Maintenance mode for severe failure (Mixed) - Balances performance and availability, by avoiding the usage of moderately degraded hosts provided that virtual machine performance is unaffected. Ensures that virtual machines do not run on severely failed hosts.
- Maintenance mode for all failures - Ensures that virtual machines do not run on partially failed hosts.
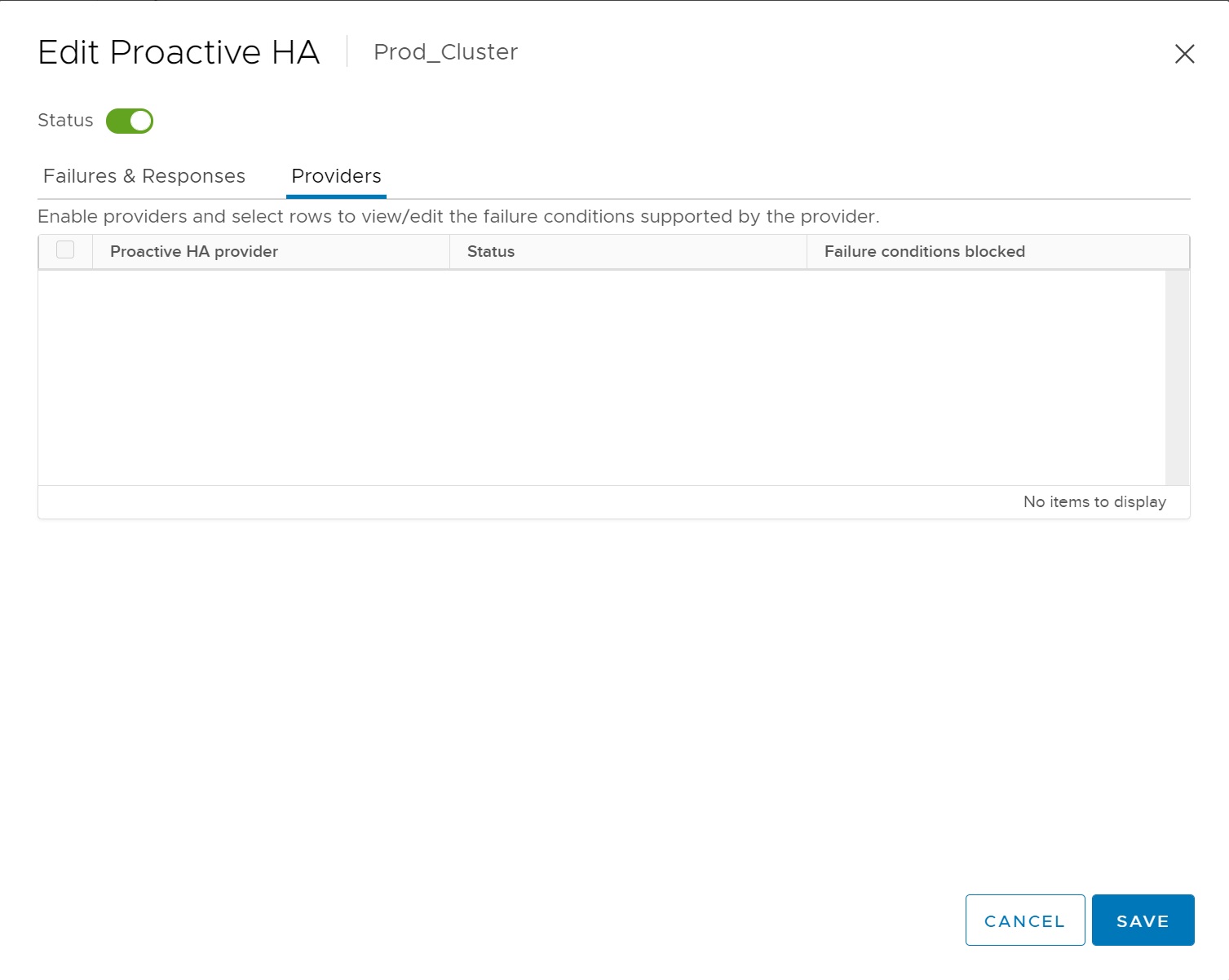
Last we come to the Providers screen, Providers appear when their corresponding vSphere Web Client plugin has been installed and the providers monitor every host in the cluster for example if you have installed ESXi on a DELL server you should see the DELL provider, these providers monitor the specific hardware for failure conditions and thus communicate with VMWare to alert that issues may occur shortly and to take action before the ESXi server fails, in other words a controlled action is taken before a hardware failure occurs. In my case I am using nested ESXi servers and thus no provider exists as its a non-supported solution.
Once you have configured the various options you are looking to get the HA/Proactive HA sreen as much green as you can.
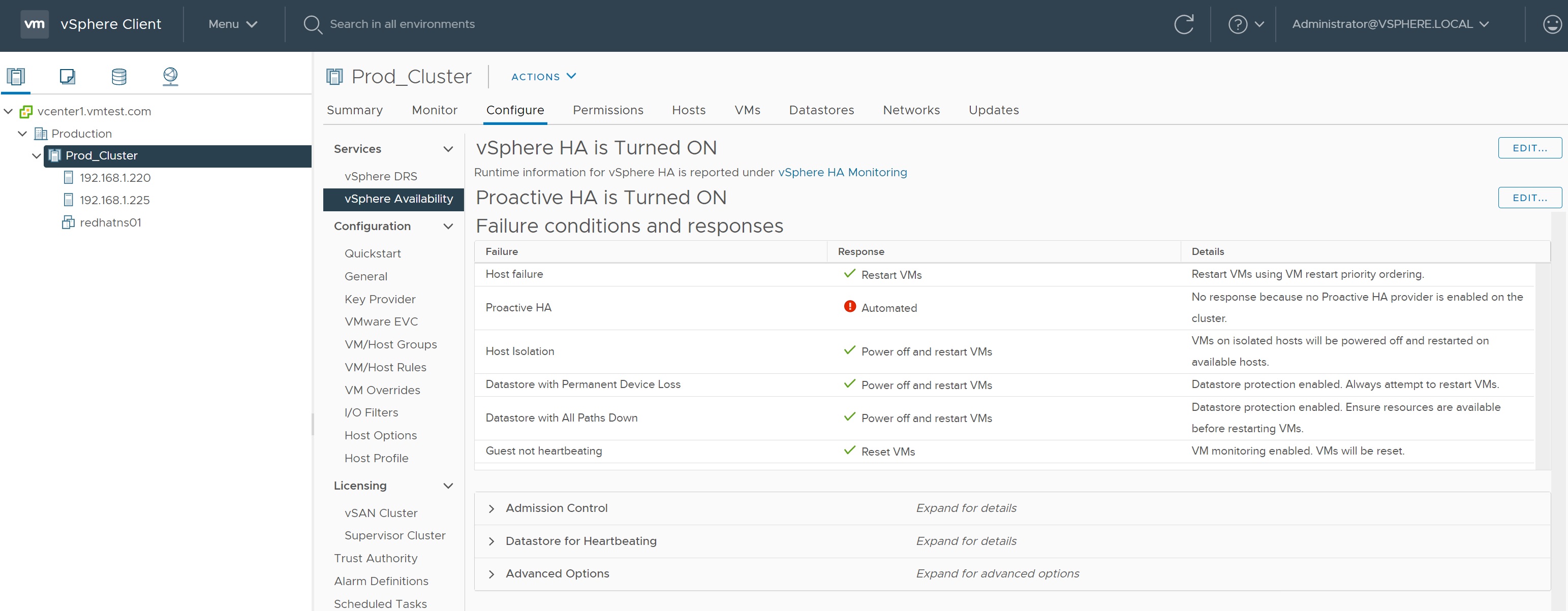
The methods to test a cluster are
- Pull the power from a ESXi server (the best test of all)
- Disconnect the network where the management port group is connected too.
- Disable the Service console interfaces
Try and test as much as you can before the solution becomes live, as it will be alot harder to test all the HA/Proactive HA features as it will be very risky when you have LIVE customers VM's running.